神经网络的编程基础
二分类(Binary Classification)
1. 输入特征的表示
在二分类任务中,输入数据通常表示为一个特征向量,例如:
- 图像数据:
- 一张RGB彩色图片可以表示为3个矩阵,分别对应红、绿、蓝三个通道的像素值。
- 例如,对于 64×64 像素的图片,RGB三个通道共包含 12,288 个像素值,它们会被拉平成一个向量输入到模型中。
- 其他类型的数据:
- 例如,金融数据可能包含用户的年龄、收入、信用评分等,每个特征都是输入向量的一部分。
在数据集表示上:
- 训练数据的输入矩阵 X 维度为 (特征数, 样本数)。
- 输出标签矩阵 Y 维度为 (1, 样本数),其中每个值为0或1。
2. 逻辑回归模型
逻辑回归是一种常见的二分类算法,它使用一个线性模型并通过sigmoid函数输出概率值:
y=σ(W^T x+b)
其中:
- x 是输入特征向量。
- W 是权重参数,b 是偏置项(这些是模型需要学习的参数)。
- σ(sigmoid 函数):将预测值映射到 (0,1) 之间,表示属于类别1的概率。
3. 训练过程
训练的目标是找到合适的参数 W 和 b,使得模型能够正确分类样本。训练过程包括以下步骤:
(1) 前向传播(Forward Propagation)
- 计算每一层的输出:
- 先计算输入与权重的加权和,并加上偏置。
- 通过激活函数(sigmoid)输出预测值。
- 预测的值是一个概率,可以用于判断类别:
- 大于 0.5,预测类别 1。
- 小于 0.5,预测类别 0。
(2) 计算损失函数
为了衡量预测结果的好坏,通常使用交叉熵损失,它能够反映预测值与真实值之间的误差。如果模型的预测结果与真实标签相差越大,损失值就越大,反之越小。
(3) 反向传播(Backward Propagation)
- 计算预测误差,得到损失函数对参数的影响(梯度)。
- 计算隐藏层和输出层的梯度,得到参数的更新方向。
- 更新参数:
- 采用梯度下降方法,根据学习率调整参数,使损失函数最小化,提高模型的分类准确率。
4. 预测
训练完成后,模型可以用于新数据的预测:
- 进行前向传播,计算预测值。
- 根据预测值的大小(是否大于0.5)来决定最终分类。
5. 总结
- 二分类问题的目标是根据输入特征预测输出标签(0或1)。
- 逻辑回归 是一种常见的二分类算法,它使用 sigmoid 函数 将预测值映射到 (0,1) 之间。
- 训练过程 包括 前向传播(计算预测值)、损失计算(衡量误差)和 反向传播(优化参数)。
- 预测阶段 直接使用训练好的模型计算输出,并根据阈值进行分类。
- 优化方法 采用 梯度下降 进行参数更新,使得模型的损失函数逐步降低,提高分类精度。
逻辑回归(Logistic Regression)
1. 逻辑回归的概念
逻辑回归是一种用于二分类问题的机器学习算法。例如,给定一张图片,模型需要判断它是否包含一只猫,并输出一个概率值:
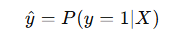
其中,ŷ 是模型的预测值,表示输入 X 属于类别 1(如“猫”)的概率。
2. 线性回归的局限
如果直接使用线性回归的形式:
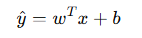
可能会导致预测值超出 0 到 1 的范围,而概率值必须介于 0 和 1 之间。
3. 采用 Sigmoid 函数
为了解决上述问题,逻辑回归使用 Sigmoid(S 形)函数:
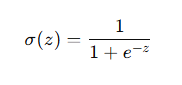
其中:
- z = w^T x + b,是输入数据的线性组合。
- σ(z) 可以确保输出值在 0 和 1 之间,使其可以表示概率。
Sigmoid 函数的特性:
- 当 z 很大时,σ(z) ≈ 1,表示类别 1 的概率接近 100%。
- 当 z 很小时,σ(z) ≈ 0,表示类别 1 的概率接近 0%。
- 当 z = 0 时,σ(0) = 0.5,表示不确定状态。
最终的假设函数(Hypothesis Function)变为:
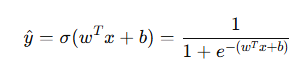
4. 逻辑回归的参数
逻辑回归的两个关键参数:
- w(权重向量):决定每个特征对最终预测的影响力。
- b(偏置):控制整体输出的偏移,使模型更灵活。
在某些表示方法中,偏置项 b 也可以通过添加一个常数特征 x₀=1 合并到 w 中,使得:
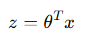
其中 θ 代表合并后的参数向量。
5. 逻辑回归的下一步
为了让模型能够正确预测,需要:
- 定义代价函数(Cost Function),衡量当前参数的好坏。
- 优化参数,通过梯度下降等方法,使代价函数最小化。
逻辑回归的代价函数(Logistic Regression Cost Function)
1. 为什么需要代价函数?
在逻辑回归中,我们希望找到最优的参数 w 和 b,使得模型的预测值 y^尽可能接近真实标签 y。为此,我们需要一个衡量误差的标准,这就是代价函数的作用。
代价函数的作用:
- 量化整个训练集上的误差;
- 作为优化目标,让梯度下降找到最优参数。
在机器学习中,代价函数通常是所有样本损失的平均值,用于衡量模型整体的表现。
2. 损失函数(Loss Function)
损失函数用于衡量单个样本的预测误差。在逻辑回归中,我们采用对数损失函数(log loss),定义如下:
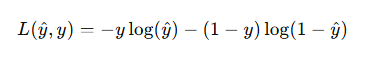
为什么使用对数损失函数?
- 平方误差(MSE)可能导致代价函数非凸,优化困难;
- 对数损失能确保代价函数是凸的,便于优化;
- 与最大似然估计(MLE)一致,具有概率解释。
该损失函数的直观理解:
- 当y=1 时,如果 y^越接近 1,损失越小;
- 当 y=0时,如果 y^越接近 0,损失越小。
这确保了模型的预测 y^ 能够更准确地趋近于 0 或 1。
3. 代价函数(Cost Function)
损失函数衡量单个样本的误差,而代价函数衡量整个训练集的平均误差,定义如下:
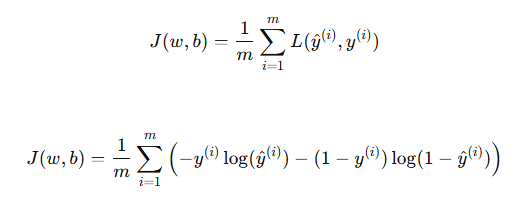
其中:
- m 是样本总数;
- y^(i)) 是第 i 个样本的预测值;
- y(i) 是第 i 个样本的真实标签。
优化目标:找到最优的 w 和 b,使得代价函数 J(w,b最小化,从而提高模型的预测准确性。
4. 什么是凸函数?为什么代价函数是凸的?
凸函数的特点:
- 只有一个全局最优点,不会陷入局部最优;
- 梯度下降法能稳定找到最优解;
- 二阶导数非负 f′′(x)≥0f''(x) \geq 0f′′(x)≥0,表明函数是向上开的。
逻辑回归的代价函数是凸函数,这意味着梯度下降可以有效地找到全局最优解。
5. 逻辑回归优化的核心
- 选择对数损失函数,确保误差衡量合理;
- 计算整个训练集的平均损失,构建代价函数;
- 由于代价函数是凸函数,梯度下降可以找到全局最优解;
- 通过不断优化 w 和 b,提高模型的预测准确性。
6.总结
- 代价函数衡量整个模型的误差,是优化的目标;
- 对数损失函数确保代价函数是凸的,优化更容易;
- 逻辑回归最终是一个优化问题,目标是最小化代价函数。
梯度下降(Gradient Descent)
梯度下降是一种用于优化函数的算法,广泛应用于机器学习和深度学习中。其核心目标是最小化代价函数(成本函数),通过迭代更新参数,使模型在训练过程中不断优化,最终得到较优的参数配置。
1. 梯度下降法的作用
梯度下降法的主要作用是 最小化代价函数 J(w, b),从而找到最优的参数 w 和 b,使得模型的预测误差最小。在机器学习任务中,如 线性回归、逻辑回归、神经网络,梯度下降都是核心的优化方法。
梯度下降的基本思想
- 计算代价函数对参数的梯度(即导数或偏导数)。
- 沿着梯度的反方向更新参数,使得代价函数值逐渐减小。
- 经过多次迭代,使参数收敛到最优解或接近最优解。
对于 凸函数(如逻辑回归的代价函数),梯度下降可以保证找到 全局最优解。对于 非凸函数(如深度学习中的损失函数),梯度下降可能会找到 局部最优解,但仍能显著提升模型的性能。
2. 梯度下降法的直观理解
梯度下降可以形象地理解为 “下山” 的过程:
- 代价函数 J(w, b) 可以看作是一个三维曲面(w 和 b 为横轴,J(w, b) 为纵轴)。
- 梯度(导数)表示该点的“斜率”,指示最陡下降的方向。
- 通过不断调整参数 w 和 b,使得 J(w, b) 下降到最小值点,即最优解。
凸函数 vs. 非凸函数
- 凸函数(如逻辑回归)
形状类似一个“碗”,无论从哪里出发,梯度下降都会收敛到 唯一的全局最优解。 - 非凸函数(如深度学习中的损失函数)
形状复杂,可能有多个局部最小值,梯度下降可能会收敛到 局部最优解。
3. 梯度下降法的计算步骤
(1) 初始化参数
- 设定初始参数 w 和 b,可以使用 随机初始化 或 固定初始值。
- 在凸函数的情况下,初始点影响不大,最终都会收敛到最优解。
(2) 计算梯度并更新参数
- 计算梯度(导数)
- 计算代价函数对参数的偏导数:
dw = ∂J(w, b)/∂wdb = ∂J(w, b)/∂b
dw和db表示参数w和b的梯度方向。
- 参数更新公式
w = w - a * dw
b = b - a * db其中,a(learning rate,学习率)决定了每次更新的步长大小。
(3) 迭代更新,直至收敛
- 不断重复计算梯度并更新参数,直到代价函数 J(w, b) 不再明显下降,达到 最优解或接近最优解。
- 训练过程中,若步长合适,参数会逐渐收敛;若步长过大,可能会跳过最优点,甚至无法收敛。
4. 学习率(Learning Rate)
学习率(a)是梯度下降中的关键超参数,它控制每次参数更新的步长。
(1) 固定学习率(手动设定)
- 过大(如 1.0):可能跳过最优点,甚至导致震荡或发散。
- 过小(如 0.0001):训练速度极慢,难以收敛。
- 常见取值:0.1、0.01、0.001,可根据实验调整。
(2) 自动调整学习率
① 学习率衰减(Learning Rate Decay)
随着训练进行,逐渐降低学习率:
- 指数衰减:每次迭代后按指数减少学习率。
- 分段衰减:训练到一定轮次后降低学习率,如每 10 轮减半。
- 余弦退火(Cosine Annealing):学习率按照余弦曲线周期性调整。
② 自适应学习率(Adaptive Learning Rate)
- AdaGrad:对较少更新的参数使用较大学习率。
- RMSprop:改进 AdaGrad,适用于非凸优化问题。
- Adam(Adaptive Moment Estimation):结合 AdaGrad 和 RMSprop,是目前最流行的优化算法。
5. 梯度下降的不同变种
(1) 批量梯度下降(Batch Gradient Descent, BGD)
- 每次计算 所有数据 的梯度后更新参数。
- 优点:稳定,保证收敛到最优解。
- 缺点:数据量大时,计算代价高,更新速度慢。
(2) 随机梯度下降(Stochastic Gradient Descent, SGD)
- 每次随机选择 一个样本 计算梯度并更新参数。
- 优点:计算效率高,适用于大规模数据。
- 缺点:梯度方向波动大,可能导致收敛不稳定。
(3) 小批量梯度下降(Mini-batch Gradient Descent)
- 结合 BGD 和 SGD,每次使用 一小批数据 计算梯度并更新参数。
- 优点:计算效率较高,且比 SGD 更稳定,适用于深度学习。
6. 总结
- 梯度下降的作用 是最小化代价函数 J(w, b),优化模型参数。
- 核心思想 是沿梯度下降方向迭代更新参数,逐步找到最优解。
- 计算步骤:
- 初始化参数
- 计算梯度
- 迭代更新,直至收敛
- 学习率 控制更新步长,选择合适的值非常重要。
- 不同梯度下降变种:
- 批量梯度下降(BGD):稳定但计算量大。
- 随机梯度下降(SGD):计算快但收敛不稳定。
- 小批量梯度下降(Mini-batch GD):平衡计算效率和稳定性。
在深度学习实践中,Mini-batch + Adam 优化器 是最常见的组合,能够有效提升训练效果和收敛速度。
导数(Derivatives)
略 自己学
更多的导数例子(More Derivative Examples)
略 自己学
计算图(Computation Graph)
计算图(Computation Graph)是深度学习中用于组织计算和梯度计算的工具。本质上,它是一种有向无环图(DAG, Directed Acyclic Graph),能够清晰地表示复杂函数的计算过程,并通过链式法则(Chain Rule)高效计算梯度。
1. 计算图的概念
- 计算图是一种 DAG(有向无环图),其中:
- 节点(Node) 代表变量或运算。
- 边(Edge) 代表数据流动和计算依赖关系。
- 前向传播(Forward Propagation):按照计算图的方向逐步计算输出结果。
- 反向传播(Backward Propagation):按照相反方向计算梯度,用于优化神经网络参数。
2. 计算图与链式法则
计算图的本质就是复合函数求导,梯度计算依赖链式法则(Chain Rule):
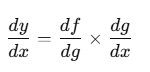
在计算图中:
- 先进行前向传播计算输出值。
- 反向传播时,梯度沿着相反方向传播,按照链式法则依次计算各变量的梯度。
4. 计算图的优势
计算图在处理复杂神经网络时非常重要,主要有以下优势:
- 自动求导:深度学习框架(如 PyTorch、TensorFlow)基于计算图实现自动梯度计算。
- 高效计算:避免重复计算,提升梯度计算效率。
- 可视化结构:直观展示数据流动和计算依赖关系,方便调试神经网络。
5. 总结
- 计算图是DAG 结构,用于表示计算过程。
- 前向传播用于计算输出,反向传播用于计算梯度。
- 本质上是链式法则的系统化应用,对于复杂神经网络的梯度计算至关重要。
在简单函数中,手算链式法则就够了,但在深度学习中,计算图是自动求导、优化模型的核心工具!
逻辑回归的梯度下降(Logistic Regression Gradient Descent)
1. 逻辑回归模型
假设样本具有两个特征 x1 和 x2,模型的线性组合计算如下:
z = w1 * x1 + w2 * x2 + b逻辑回归的输出为:
y_hat = a = σ(z) = 1 / (1 + e^(-z))损失函数定义如下:
L(a, y) = - (y * log(a) + (1 - y) * log(1 - a))代价函数(多个样本的平均损失):
J(w, b) = (1 / m) * Σ L(a^(i), y^(i))2. 计算梯度
使用反向传播计算梯度:
- 计算损失函数关于 a 的导数:
dL/da = -y/a + (1 - y)/(1 - a)- 计算 z 的梯度:
dL/dz = (dL/da) * (da/dz) = (a - y)- 计算参数 w1, w2, b 的梯度:
dw1 = x1 * dz, dw2 = x2 * dz, db = dz3. 梯度下降更新参数
利用学习率 α 进行参数更新:
w1 := w1 - α * dw1
w2 := w2 - α * dw2
b := b - α * db4. m 个样本的梯度下降
在之前,我们只计算了单个样本的梯度下降,现在我们推广到 m 个训练样本。全局代价函数 J(w, b) 的定义如下:
J(w, b) = (1 / m) * Σ L(a^(i), y^(i))计算梯度时,对每个样本计算预测值,并求平均梯度:
J = 0, dw1 = 0, dw2 = 0, db = 0
for i = 1 to m:
z(i) = w * x(i) + b
a(i) = sigmoid(z(i))
J += -[y(i) * log(a(i)) + (1 - y(i)) * log(1 - a(i))]
dz(i) = a(i) - y(i)
dw1 += x1(i) * dz(i)
dw2 += x2(i) * dz(i)
db += dz(i)
J /= m
dw1 /= m
dw2 /= m
db /= m然后进行梯度更新:
w1 := w1 - α * dw1
w2 := w2 - α * dw2
b := b - α * db5. 代码优化与向量化
上述方法使用两个 for 循环,一个遍历所有样本,另一个遍历所有特征。如果特征数较大,代码效率较低。在深度学习中,为了适应大规模数据集,我们通常使用 向量化 方法,而非显式 for 循环。向量化能够极大地加速计算,提高梯度下降算法的效率。
在接下来的部分,我们将探讨如何使用向量化方法优化逻辑回归的梯度下降算法,使其更加高效。
向量化(Vectorization)
在深度学习中,向量化是提高计算效率的关键技巧之一。简单来说,向量化指的是将代码中的显式 for 循环转化为能够在底层高效并行计算的向量操作。通过使用像 numpy 这样的库,可以使操作直接作用于整个向量或矩阵,而不是依赖逐一元素的循环计算。
向量化的例子:
- 计算
w^T * x + b:这是逻辑回归中的常见操作,如果用for循环实现,会显得非常慢。相对的,使用numpy的np.dot(w, x) + b可以显著加速计算。
z = np.dot(w, x) + b # 向量化实现- 计算
np.dot(a, b)和循环版:举例来说,计算两个向量的点积,非向量化的实现会使用for循环来遍历两个向量的每个元素。而使用numpy.dot函数实现时,速度会快得多。
c = np.dot(a, b) # 向量化实现通过使用 numpy.dot,计算速度比 for 循环快约300倍。
为什么向量化更有效?
- 向量化操作通常依赖底层的优化,如 SIMD(单指令多数据),这使得代码能在 CPU 或 GPU 上并行执行,处理速度更快。
- 通过避免使用
for循环,可以减少代码的冗余操作,提高代码的可读性和维护性。
更多向量化的例子:
- 矩阵与向量乘法:计算
u = A * v,如果使用for循环,会写成两层循环(依次计算每个元素),而通过numpy的np.dot(A, v),可以直接实现高效计算。
u = np.dot(A, v) # 向量化矩阵乘法- 对向量做指数运算:计算向量每个元素的指数,如
u = exp(v),可以直接通过numpy.exp(v)实现,而无需for循环逐个计算。
u = np.exp(v) # 向量化指数操作总结:
- 向量化能显著提高计算效率,尤其是在处理大数据集时,它能减少运行时间。
- 在实现神经网络或逻辑回归等模型时,尽量避免使用
for循环,利用numpy的内置函数可以提高代码性能。
向量化逻辑回归(Vectorizing Logistic Regression)
1. 目标
通过向量化,使用矩阵运算一次性处理所有训练样本的计算,从而提升代码执行速度。特别是计算逻辑回归模型的预测值,以及利用梯度下降进行优化时,可以避免冗余的for循环。
2. 向量化的前向传播过程
- 输入数据: 假设输入数据是一个矩阵 X,它的形状为 n x m,其中 n 是特征数量,m 是样本数量。
计算 z: 对于每个样本,逻辑回归的预测公式为 z = w^T * x + b。通过向量化计算,我们可以一次性计算所有样本
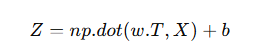
其中,np.dot(w.T, X) 是将 w 的转置与输入矩阵 X 相乘,得到一个 1 x m 的向量,然后加上偏置项 b(在Python中,b 会自动广播成一个 1 x m 的向量)。
计算 a (激活函数): 得到 z 后,我们应用激活函数(sigmoid函数),计算 a:
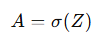
其中,A 是所有样本的激活值,它的形状为 1 x m。
3. 优点
通过这种向量化方式,我们避免了显式的for循环,使用一次矩阵运算就能计算出所有样本的预测值。Python中的广播机制使得加上偏置项 b 变得非常简洁,无需手动扩展 b。
4. 后续步骤
接下来可以进行反向传播,通过类似的向量化方式计算梯度,以便进行模型的优化。这将是下一步的重点。
总结一下,通过向量化方法,我们能高效地计算所有样本的 z 和 a,避免了传统的逐个样本处理的低效方式。这种方法不仅能加速训练过程,还为处理更复杂的神经网络计算提供了基础。
向量化逻辑回归的梯度计算(Vectorizing Logistic Regression's Gradient)
以下是向量化的关键步骤和公式总结:
- 计算预测值:
对于每个训练数据,计算其预测值,即逻辑回归模型的输出。这个预测值可以通过矩阵运算完成,不需要对每个样本逐一计算。 - 计算梯度:
- 对于每个训练数据的误差,我们定义了
dZ = A - Y,这是一个m维的行向量,表示每个样本的误差。 - 对于
dW(权重梯度)和dB(偏置梯度),我们可以直接通过矩阵运算来计算:
- dB:
dB = 1/m * np.sum(dZ)
这是计算所有训练样本误差的均值。 - dW:
dW = 1/m * np.dot(X, dZ.T)
这是通过矩阵乘法计算所有样本的梯度,X是输入特征矩阵,dZ是误差行向量。
- 更新参数:
- 使用计算得到的梯度来更新模型的参数:
w := w - α * dWb := b - α * dB
其中α是学习率。
- 去除
for循环:
向量化的关键是在计算梯度时不使用for循环,而是利用矩阵运算一次性计算出所有样本的梯度,这使得整个过程更加高效。
最终,通过一次矩阵运算即可同时计算所有训练数据的梯度,从而避免了对训练集的逐个循环处理,使得逻辑回归的梯度下降算法更加高效。
在 Python 实现中,利用 numpy 的矩阵运算(如 np.dot 和 np.sum)可以非常轻松地实现这些向量化操作。这种方式显著提高了性能,尤其是在处理大规模数据集时。
Python中的广播机制(Broadcasting in Python)
请自学
关于 Python与numpy向量的使用(A note on python or numpy vectors)
请自学
逻辑回归损失函数详解(Explanation of logistic regression cost function)
选修课没选2333