浅层神经网络
神经网络概述(Neural Network Overview)
- 逻辑回归回顾
- 逻辑回归模型的计算过程:输入特征 x,权重 w 和偏置 b,计算 z=w^Tx+b 之后通过 sigmoid 激活函数得到 a=σ(z),然后计算损失函数 L(a,y)。
- 神经网络的构造
- 逻辑回归可以看作是一个单一的神经元,而神经网络是由多个这样的神经元堆叠而成的。
- 神经网络的每一层都包含权重矩阵 W[m] 和偏置向量 b[m]。
- 计算前向传播:
- 第一层: z[1]=W[1]x+b[1] ,然后 a[1]=σ(z[1])。
- 第二层: z[2]=W[2]a[1]+b[2],然后 a[2]=σ(z[2]) 作为最终输出。
- 反向传播
- 计算损失函数的梯度 dL(a[2],y),然后逐层计算偏导数 da[2]、dz[2]、dW[2]、db[2] 等,依次向前层传播,调整神经网络的参数。
- 理解神经网络的本质
- 本质上是多个逻辑回归单元的叠加,每一层计算 z 和 a,最终通过多层的组合学习更复杂的映射关系。
神经网络的表示(Neural Network Representation)
在本节中,我们将探讨神经网络的具体含义,并详细介绍其各个组成部分及符号表示。
1. 神经网络的层次结构
神经网络由多个层组成,主要包括 输入层、隐藏层和输出层:
- 输入层
由输入特征组成,例如 x1、x2、x3。它们被竖直堆叠在一起,形成输入层。输入层的作用是将数据提供给网络的下一层。 - 隐藏层
介于输入层和输出层之间,包含多个神经元(如图 3.2.1 中的四个节点)。
为什么称为“隐藏层”? 在监督学习中,我们的训练集包含输入 x 和目标输出 y,但隐藏层的具体值在训练数据中是不可见的。因此,这些中间层被称为“隐藏”层。 - 输出层
负责生成最终的预测结果,它与逻辑回归的输出类似。在图 3.2.1 中,输出层只有一个神经元,用于计算最终的预测值。
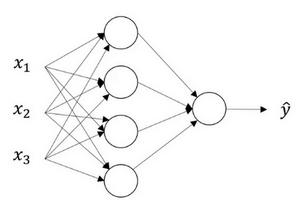 图3.2.1
图3.2.1
2. 神经网络的符号表示
在描述神经网络的计算过程时,我们引入了一些符号来表示不同层的值:
- 激活值(Activation Values)
- 输入特征向量 x 可用 a(0) 表示,表示输入层的激活值。
- 隐藏层的输出称为 a(1),每个神经元的输出分别记作:
a(1) =
[ a(1)1
a(1)2
a(1)3
a(1)4 ]在 Python 代码中,这个激活值可以表示为一个 4×1 的列向量或矩阵。
- 输出层的激活值(即预测值)表示为 a(2)。
- 权重(Weights)和偏置(Bias)
每一层的计算都与 权重矩阵 和 偏置向量 相关:
- 隐藏层的参数:
- W(1)(4×3):连接输入层到隐藏层的权重矩阵(4 个神经元,3 个输入特征)。
- b(1)(4×1):隐藏层的偏置向量。
- 输出层的参数:
- W(2)(1×4):连接隐藏层到输出层的权重矩阵(输出层有 1 个神经元,隐藏层有 4 个)。
- b(2)(1×1):输出层的偏置向量。
3. 神经网络的层数定义
在神经网络的层数定义上,有两个重要的约定:
- 计算层数时,输入层不计入总层数。因此,本例中:
- 隐藏层是第 1 层
- 输出层是第 2 层
- 该神经网络被称为“两层神经网络”。
- 另一种表达方式是:
- 输入层称为第 0 层(a(0))
- 隐藏层称为第 1 层(a(1))
- 输出层称为第 2 层(a(2))
- 这样看,该神经网络总共有 三层,但由于输入层不算在神经网络的标准层数中,它仍被称为“两层神经网络”。
计算一个神经网络的输出(Computing a Neural Network's output)
1. 神经网络的计算流程
一个具有 单隐藏层 的神经网络通常由以下部分组成:
- 输入层:接收特征数据,通常是一个向量。
- 隐藏层:包含多个神经元,每个神经元进行加权求和并通过 激活函数 处理。
- 输出层:接收隐藏层的输出,并进一步计算最终的预测值。
2. 计算隐藏层的输出
神经网络的计算过程可以分为两个核心步骤:
(1)单个神经元的计算
每个神经元的计算类似于逻辑回归:
- 加权求和(线性变换):z = W^Tx + b
- 激活函数处理(非线性变换):a = σ(z)
其中,σ(z) 通常使用 sigmoid、ReLU 或其他激活函数。
(2)多个神经元的计算
在隐藏层中,有多个神经元同时进行计算:
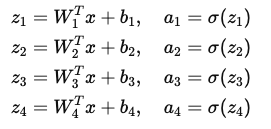
这意味着我们可以把所有计算用 矩阵运算 统一表示。
多样本向量化(Vectorizing across multiple examples)
核心思想是:
- 单个训练样本的计算是逐步进行的,从输入层到隐藏层,再到输出层。
- 如果有 m 个训练样本,每个样本 x(i) 都需要单独计算,传统方式需要用 for 循环进行逐个计算,效率低。
- 通过矩阵运算,可以一次性计算所有 m 个训练样本的结果,提高效率。
向量化计算的具体实现
- 矩阵 X 组织训练样本
- 将 m 个训练样本 x(i) 组织成矩阵 X:
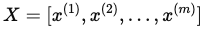
- 这样 X 是一个 (n, m) 维矩阵,其中 n 是输入特征数,m 是样本数。
- 隐藏层计算
计算隐藏层的 Z:
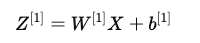
- 其中:
- W^{[1]} 是 (h, n) 维矩阵,h 是隐藏层神经元个数。
- X 是 (n, m) 维矩阵。
- b^{[1]} 是 (h, 1) 维的偏置向量,通常会广播成 (h, m) 维以适配运算。
计算隐藏层的激活值:
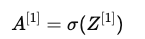
- 这里 σ() 是激活函数,作用于矩阵 Z^{[1]} 的每个元素。
- 输出层计算
- 计算 Z^{[2]}:
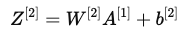
- 计算输出:
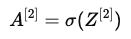
- 这里 A^{[2]} 代表最终的预测值。
这样,通过矩阵运算,可以一次性计算所有样本的结果,而不需要 for 循环,极大提高了计算效率。这也是深度学习优化计算的关键技术之一。
理解矩阵的行列
- 水平方向(列) 代表不同的训练样本(1 到 m)。
- 垂直方向(行) 代表神经网络不同的单元或特征(输入特征、隐藏层神经元等)。
- 这种表示法使得矩阵运算符合逻辑回归中的矩阵计算方式,从而保证计算的正确性。
总结
- 通过向量化,可以一次性处理多个样本,提高计算效率。
- 关键是组织好输入矩阵 X,并在每一层计算时使用矩阵运算,而不是逐个样本计算。
- 这种方法是深度学习中计算加速的重要手段,也是 GPU 并行计算的基础。
向量化实现的解释(Justification for vectorized implementation)
1. 从单样本到多样本的前向传播计算
在单个样本的前向传播过程中,第 1 层的线性变换可以表示为:
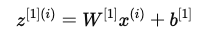
其中:
- W[1] 是一个权重矩阵,
- x(i) 是第 i 个输入样本的列向量,
- b[1] 是偏置列向量,
- z[1](i) 是计算得到的线性变换结果。
对于多个样本,我们可以分别计算,它们的计算结构是相同的。因此,我们可以将所有样本合并到一个矩阵 X 中,并一次性完成所有样本的计算。
2. 矩阵形式的推导
将所有训练样本横向堆叠到矩阵 X 的各列中:
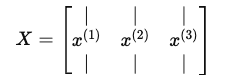
对所有样本同时计算前向传播:
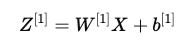
其中:
- Z[1] 仍然是一个矩阵,它的每一列对应一个样本的计算结果。
- 偏置项 b[1] 是一个列向量,它需要与矩阵 Z[1] 的每一列相加。
在 Python 中,广播机制(broadcasting)可以自动将 b[1] 复制到每一列,使得运算正确执行。
这样,我们就完成了 多个样本的前向传播计算,而无需显式使用循环,极大地提高了计算效率。
3. 向量化计算的推广
类似的逻辑可以推广到神经网络的所有层次。
一般化的前向传播计算
神经网络的前向传播每一层都遵循相同的模式:
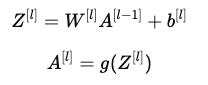
其中:
- A[l] 是第 l 层的激活值,
- W[l] 和 b[l] 分别是权重矩阵和偏置项,
- g(⋅) 是激活函数(如 sigmoid、ReLU、tanh 等)。
因此,不论神经网络有多少层,我们都可以利用相同的矩阵计算方式,避免使用显式循环。
激活函数(Activation functions)
在使用神经网络时,需要决定隐藏层和输出层分别使用哪种激活函数。之前的课程主要使用了 sigmoid 激活函数,但在某些情况下,其他激活函数可能表现更好。
在神经网络的前向传播中,隐藏层和输出层的激活值由激活函数决定。例如,在之前的例子中,隐藏层的计算为:
- a1 = sigmoid(z1)
- a2 = sigmoid(z2)
这里的 sigmoid 函数是一个激活函数,其数学表达式为:
- a = 1 / (1 + exp(-z))
更一般地,隐藏层可以使用不同的激活函数 g(z),这不仅限于 sigmoid。比如 tanh(双曲正切)函数通常比 sigmoid 更优:
- a = tanh(z) = (exp(z) - exp(-z)) / (exp(z) + exp(-z))
tanh 实际上是 sigmoid 的变形版本,经过缩放和平移后,其输出范围在 -1 到 1 之间。研究表明,在隐藏层使用 tanh 通常优于 sigmoid,因为其均值更接近零,有助于神经网络的训练效果。
在二分类问题中,输出层通常仍然使用 sigmoid,因为其输出范围在 0 到 1 之间,更符合概率解释:
- g(z2) = sigmoid(z2)
这说明,在神经网络的不同层,可以选择不同的激活函数。例如,隐藏层可以使用 tanh,而输出层使用 sigmoid。
其他激活函数
sigmoid 和 tanh 的一个共同问题是,当 z 取值很大或很小时,梯度趋近于零,导致梯度下降变慢。这就是所谓的 梯度消失(vanishing gradient)问题。
为了克服这个问题,另一种常用的激活函数是 ReLU(Rectified Linear Unit):
- a = max(0, z)
在 ReLU 中,当 z > 0 时,导数恒为 1,而当 z < 0 时,导数为 0。这种特性使得神经网络在大多数情况下训练更快。不过,ReLU 存在一个问题,即当 z < 0 时,神经元的梯度为 0,可能会导致某些神经元“死亡”(即永远不会被更新)。
为了解决 ReLU 在负值部分的缺陷,出现了一种变体:Leaky ReLU:
- a = max(0.01z, z)
与 ReLU 不同,Leaky ReLU 在 z < 0 时仍然有一个较小的斜率(如 0.01),可以避免神经元死亡问题。尽管 Leaky ReLU 在某些情况下效果更好,但工业界仍然更常使用 ReLU。
选择激活函数的经验法则
- 二分类问题:输出层通常使用 sigmoid,因为输出值需要在 0 到 1 之间。
- 隐藏层默认选择:ReLU 是最常见的默认激活函数,适用于大多数情况。如果不确定使用哪种激活函数,可以优先尝试 ReLU。
- 可能的优化选择:
- 在某些情况下,tanh 可能比 ReLU 表现更好,尤其是在隐藏层。
- Leaky ReLU 可能优于 ReLU,但实际应用较少。
结论
- sigmoid 主要用于输出层的二分类问题。
- tanh 适用于隐藏层,通常比 sigmoid 更好。
- ReLU 是最常用的隐藏层激活函数,适用于大多数深度学习任务。
- Leaky ReLU 在某些情况下比 ReLU 更优,但使用较少。
- 选择激活函数时,最好的方法是通过实验进行验证,看哪种方法在验证集上表现更好。
为什么需要非线性激活函数?(why need a nonlinear activation function?)
在神经网络中,激活函数的作用是引入非线性,使得神经网络可以学习复杂的映射关系。如果不使用非线性激活函数,无论网络有多少层,它最终都只能表示一个线性变换,无法学习复杂的特征。
非线性激活函数的作用
为了使神经网络具有更强的表达能力,必须在隐藏层引入非线性,常见的非线性激活函数包括:
ReLU(修正线性单元)
- g(z)=max(0,z)
- 计算简单,收敛快
- 解决 Sigmoid 梯度消失问题
- 适用于大多数深度神经网络
Sigmoid(S 形激活函数)
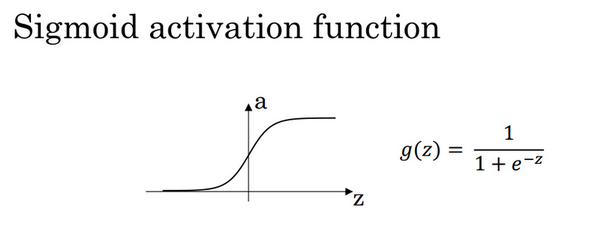
- 输出范围 (0, 1),适合二分类问题
- 容易导致梯度消失,不适合深层网络
Tanh(双曲正切函数)
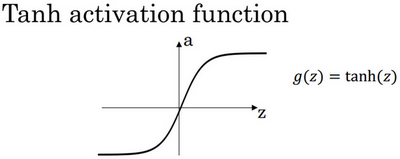
- 输出范围 (-1, 1),均值为 0,梯度更大
- 适用于隐藏层,但仍可能存在梯度消失问题
Leaky ReLU
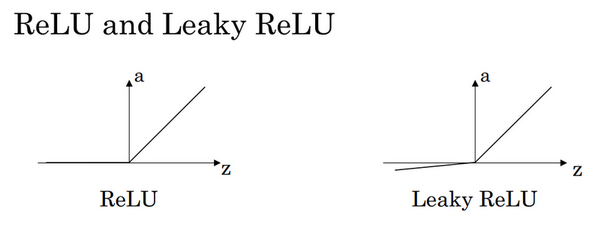
- 解决 ReLU 的“死亡神经元”问题
- 适用于深层网络
什么时候可以使用线性激活函数?
虽然隐藏层不能使用线性激活函数,但在输出层,有些情况下可以使用:
- 回归问题(输出是连续实数)
- 特殊情况(如自动编码器的压缩层)
例如,如果神经网络用于房价预测,输出值可以取任何实数,可以使用线性激活函数:g(z)=z。但如果房价不能为负数,可以使用 ReLU 作为输出层激活函数。
总结
- 隐藏层不能使用线性激活函数,否则网络等效于单层神经网络,无法学习复杂模式。
- 必须使用 ReLU、Tanh、Sigmoid 或其他非线性激活函数,使网络具有更强的表达能力。
- 在回归任务中,输出层可以使用线性激活函数,但对于分类问题一般使用 Sigmoid(单分类)或 Softmax(多分类)。
- ReLU 是目前深度学习中最常用的激活函数,适用于大多数任务。
激活函数的导数(Derivatives of activation functions)
请自行求导数
神经网络的梯度下降(Gradient descent for neural networks)
1. 参数定义
假设一个单隐层神经网络,参数如下:
- 输入层:特征数 nx
- 隐藏层:神经元数 n[1]
- 输出层:神经元数 n[2]
参数的维度
- 权重矩阵
- W[1] 形状:(n[1],nx)
- W[2] 形状:(n[2],n[1])
- 偏置向量
- b[1] 形状:(n[1],1)
- b[2] 形状:(n[2],1)
2. 代价函数
对于二分类任务,代价函数(Cost Function)定义为:
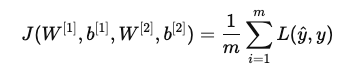
其中,损失函数(Loss Function) 和逻辑回归相同。
3. 正向传播(Forward Propagation)
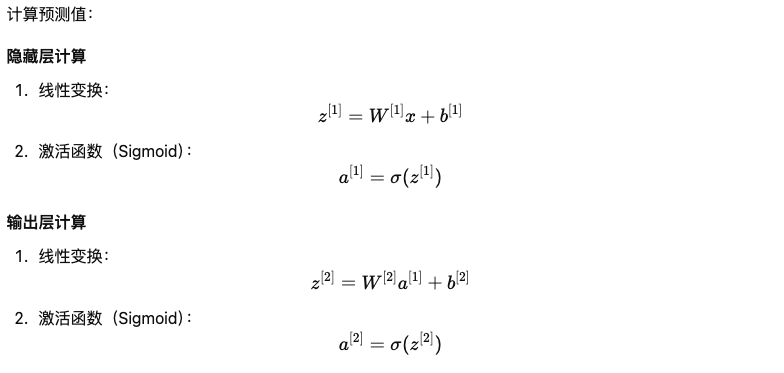
4. 反向传播(Back Propagation)
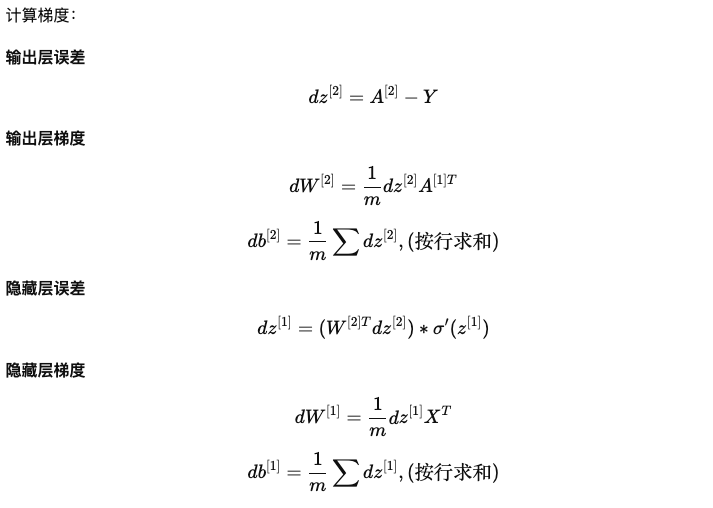
5. 参数更新
使用梯度下降更新参数:
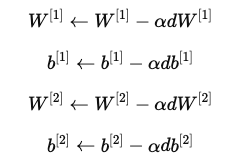
其中 α是学习率。
6. 关键点
- 参数初始化:避免初始化为零,否则所有神经元的更新都相同,无法学习不同的特征。
- 向量化计算:使用 NumPy 进行矩阵运算,加速计算并减少循环。
- 维度匹配:确保矩阵相乘时的形状正确,避免维度错误。
直观理解反向传播(Backpropagation intuition)
1. 逻辑回归的反向传播
逻辑回归的前向传播计算:
- 计算线性组合
z = w^T * x + b - 计算激活函数
a = σ(z) - 计算损失
L(a, y)
反向传播计算:
- 计算损失对激活值
a的梯度da = dL/da - 计算
dz = da * σ'(z),即dz = a - y - 计算
dw = dz * x,db = dz
2. 神经网络的反向传播
相比逻辑回归,神经网络的反向传播多了一层隐藏层:
- 前向传播:
- 计算
z^[1] = W^[1] * x + b^[1] - 计算
a^[1] = g(z^[1]) - 计算
z^[2] = W^[2] * a^[1] + b^[2] - 计算
a^[2] = g(z^[2]) - 计算损失
L(a^[2], y)
- 反向传播:
- 计算输出层的梯度
dz^[2] = a^[2] - y - 计算
dW^[2] = dz^[2] * (a^[1])^T - 计算
db^[2] = dz^[2] - 计算
dz^[1] = W^[2]^T * dz^[2] * g'[z^[1]] - 计算
dW^[1] = dz^[1] * x^T - 计算
db^[1] = dz^[1]
3. 关键点总结
- 反向传播利用 链式法则,逐层计算梯度。
- 矩阵计算时要注意 维度匹配,例如
dW^[1]需要是(n^[1], n^[0])。 - 计算梯度时,会涉及 逐元素相乘 (
*表示逐元素相乘)。 - 梯度下降 需要对
W和b进行更新。 - 参数初始化 不能全为 0,而是随机初始化,避免所有神经元学习相同的特征。
4. 理解建议
吴恩达的建议是,不一定要完全掌握数学推导,但要有直觉:
- 反向传播就是通过 梯度计算,让神经网络的参数逐步优化。
- 误差 从输出层往输入层传播,逐层计算梯度并更新参数。
- 关键在于 矩阵维度匹配 和 链式法则 的应用。
随机初始化(Random+Initialization)
这一节讲的是随机初始化(Random Initialization),核心思想是:神经网络的权重不能全部初始化为0,而应该随机初始化。
1. 为什么不能全部初始化为0?
- 逻辑回归可以将权重初始化为0,但神经网络不可以。
- 如果权重
W^[1]初始化为全 0,那么所有隐藏层神经元都会计算相同的值。 - 在反向传播中,它们的梯度也会一样,更新的权重
W^[1]仍然是对称的,导致所有隐藏单元学到的都是相同的特征。 - 最终,多个隐藏单元和只有 1 个隐藏单元没有区别,失去了神经网络的优势!
2. 解决方案:随机初始化
- 让
W随机初始化为很小的值,保证不同隐藏单元计算不同的函数,打破对称性 (symmetry breaking problem)。 b可以初始化为 0,因为它不会影响对称性问题。
Python 代码示例:
W1 = np.random.randn(2,2) * 0.01 # 小的随机数
b1 = np.zeros((2,1))
W2 = np.random.randn(1,2) * 0.01
b2 = np.zeros((1,1))np.random.randn()生成高斯分布的随机数。- 乘上
0.01是为了防止W过大,导致z过大,让sigmoid或tanh进入饱和区域,造成梯度消失。
3. 为什么选择 0.01?
- 如果
W过大,那么z = W * x + b也会变大,激活函数sigmoid(z)或tanh(z)可能进入饱和区,导致梯度接近 0,学习变慢(梯度消失问题)。 - 如果
W过小,梯度也可能太小,导致学习速度变慢。 - 选择
0.01只是一个经验值,适用于浅层神经网络。 - 对于更深的神经网络,可能需要调整
0.01,比如使用Xavier或He初始化方法(下一节介绍)。
4. 关键总结
✅ 不要 把 W 全部初始化为 0,否则隐藏单元学不到不同的特征。
✅ 使用np.random.randn() 生成小的随机值,通常乘以 0.01。
✅ b 可以初始化为 0,不会影响学习。
✅ 避免 过大的 W,否则梯度消失,学习速度变慢。
✅ 对于深层神经网络,可能需要更合适的初始化策略(比如 Xavier 或 He)。