解释结构模型例子(修改中)
该研究通过从定性分析到定量建模的完整流程,构建了解释结构模型(ISM)。
以下是该研究的具体实施过程总结:
1.确定研究对象与影响因素(定性阶段)
研究通过文献资料法和访谈调查法,确定了线上教学效果的评价维度和具体指标。
确立维度: 研究将影响因素划分为四个主要层面:学生层面、教师层面、课程层面、平台层面。
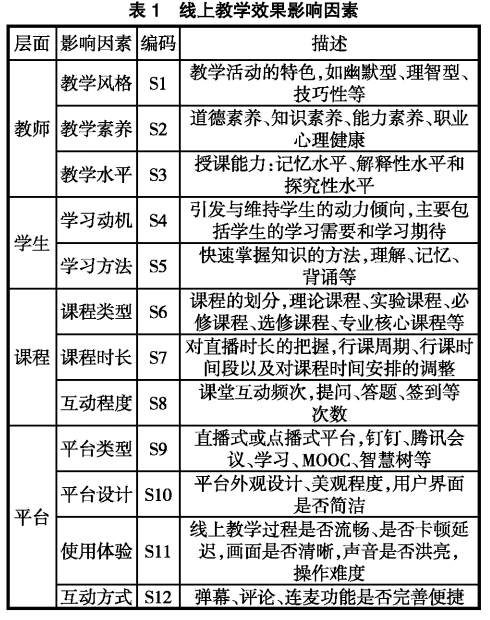
筛选因子: 归纳出12个主要影响因素(编号S1至S12),包括教学风格、教学素养、教学水平、学习动机、学习方法、课程类型、课程时长、互动程度、平台类型、平台设计、使用体验、互动方式。
2.数据收集与关系判定
问卷调查: 以河北农业大学的258名本科生为调查对象发放问卷 。
二元关系判定: 让调查对象评判这12个要素之间的相互关系(即判断因素A是否直接影响因素B) 。
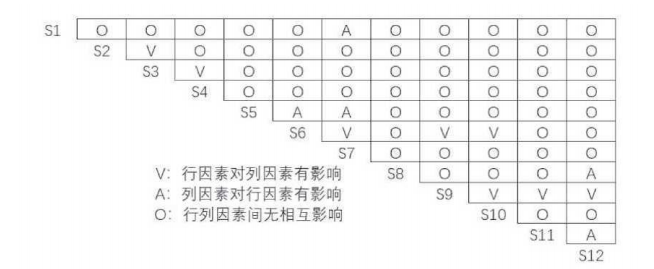
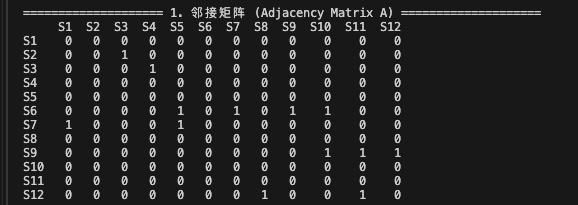
建立邻接矩阵: 根据调查数据,建立邻接矩阵(Adjacency Matrix),用1表示有直接影响,用0表示无直接影响。
3.构建ISM模型(定量计算阶段)
利用矩阵运算将复杂的因素关系结构化:
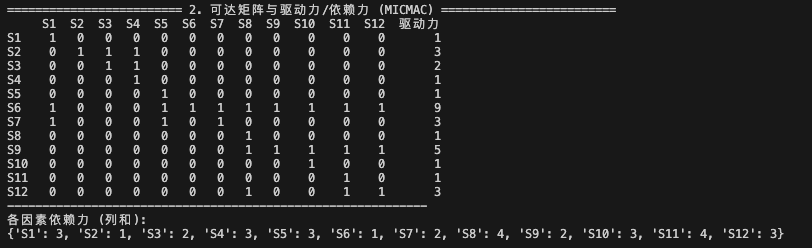
计算可达矩阵: 在邻接矩阵的基础上,通过布尔代数运算推导出可达矩阵(Reachability Matrix),确定任意要素的“可达集” R(Si)(该要素能影响到的集合)和“先行集” A(Si)(能影响该要素的集合) 。
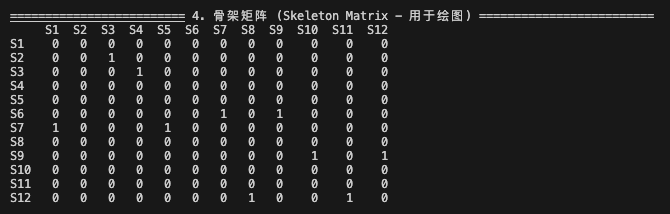
计算骨架矩阵:
层级划分: 依据 R(Si) = R(Si)并A(Si)的条件,自上而下进行层级抽取,将12个因素划分为四个层级:
说明:L1 为最顶层(结果层),L_Max 为最底层(原因层)
Level 1: S1(教学风格), S4(学习动机), S5(学习方法), S8(互动程度), S10(平台设计), S11(使用体验)
Level 2: S3(教学水平), S7(课程时长), S12(互动方式)
Level 3: S2(教学素养), S9(平台类型)
Level 4: S6(课程类型)

4.模型可视化与分析
绘制递阶结构图: 根据计算出的骨架矩阵和层级关系,绘制出多层递接结构模型图(有向拓扑图),直观展示各因素间的逻辑链条。

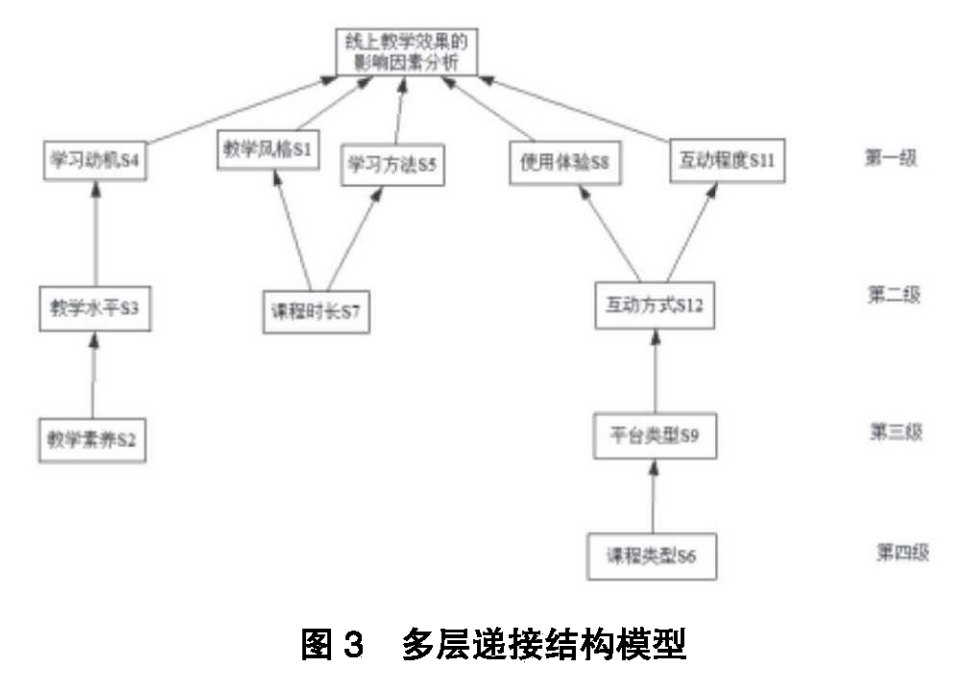
路径分析:
分析出“学习动机”和“互动程度”等是直接影响教学效果的表层因素 。
指出“教学水平”和“教学素养”是间接影响因素,它们通过激发学习兴趣来提升效果。
明确“课程类型”处于最底层,说明线上教学模式的选择需基于课程的根本性质(如理论课与实验课的区别)。
5.提出对策建议
基于模型分析结果,从三个方面提出了改进策略:
师生能力: 加强教师线上教学素养及学生自主学习能力的培养。
教学技能: 强化互动训练,利用幽默感、小测验等控制节奏。
资源整合: 根据课程性质(根源因素)灵活选择直播或录播形式,并完善教材和考勤制度。
代码实现
import numpy as np
import pandas as pd
# ================= 配置与初始化 =================
# 设置pandas显示选项,确保中文对齐和显示完整
pd.set_option('display.max_columns', 20)
pd.set_option('display.width', 1000)
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
pd.set_option('display.max_rows', None)
# 定义因素字典 (带中文含义)
factors_dict = {
'S1': '教学风格', 'S2': '教学素养', 'S3': '教学水平', 'S4': '学习动机',
'S5': '学习方法', 'S6': '课程类型', 'S7': '课程时长', 'S8': '互动程度',
'S9': '平台类型', 'S10': '平台设计', 'S11': '使用体验', 'S12': '互动方式'
}
codes = list(factors_dict.keys())
labels = [f"{k}" for k in factors_dict.keys()] # 简化显示,只显示代号,表头不易乱
full_labels = [f"{k}({v})" for k, v in factors_dict.items()] # 完整标签用于最终报告
n = len(codes)
# 定义SSIM关系 (基于之前的分析)
# 格式: (Row_Index, Col_Index, Type)
# V: Row->Col, A: Col->Row
relationships = [
(0, 6, 'A'), # S1-S7: A
(1, 2, 'V'), # S2-S3: V
(2, 3, 'V'), # S3-S4: V
(4, 5, 'A'), # S5-S6: A
(4, 6, 'A'), # S5-S7: A
(5, 6, 'V'), # S6-S7: V
(5, 8, 'V'), # S6-S9: V
(5, 9, 'V'), # S6-S10: V
(7, 11, 'A'), # S8-S12: A
(8, 9, 'V'), # S9-S10: V
(8, 10, 'V'), # S9-S11: V
(8, 11, 'V'), # S9-S12: V
(10, 11, 'A') # S11-S12: A
]
# ================= 核心计算函数 =================
def calc_adjacency(n, rels):
"""计算邻接矩阵"""
adj = np.zeros((n, n), dtype=int)
for r, c, t in rels:
if t == 'V': adj[r, c] = 1
elif t == 'A': adj[c, r] = 1
return adj
def calc_reachability(adj):
"""计算可达矩阵 (A+I)^k"""
n = adj.shape[0]
identity = np.eye(n, dtype=int)
reach = (adj + identity > 0).astype(int)
while True:
new_reach = (np.matmul(reach, reach) > 0).astype(int)
if np.array_equal(new_reach, reach):
return reach
reach = new_reach
def calc_skeleton(reach):
"""计算骨架矩阵 (去除传递性冗余边)"""
n = reach.shape[0]
skeleton = reach.copy()
np.fill_diagonal(skeleton, 0) # 去除自回路
# 核心算法: 如果 i->k->j 存在,则移除 i->j
# 优化算法: 直接矩阵运算 S = R - (R-I)^2 - I (并不完全通用,建议用循环校验法)
for i in range(n):
for j in range(n):
if i == j or skeleton[i, j] == 0: continue
# 检查中间点
for k in range(n):
if k != i and k != j:
if reach[i, k] == 1 and reach[k, j] == 1:
skeleton[i, j] = 0 # 移除直接连接
break
return skeleton
def calc_levels(reach):
"""层级划分 (Level Partition)"""
# 转换为DataFrame方便操作
df = pd.DataFrame(reach, index=np.arange(n), columns=np.arange(n))
active_nodes = list(df.index)
levels = {}
current_level = 1
while active_nodes:
level_nodes = []
# 对当前剩余的每一个节点进行判断
for node in active_nodes:
# R(Si): 可达集 (这一行是1的列)
reach_set = set(df.columns[df.loc[node] == 1]) & set(active_nodes)
# A(Si): 先行集 (这一列是1的行)
ante_set = set(df.index[df.loc[:, node] == 1]) & set(active_nodes)
# 交集
intersection = reach_set.intersection(ante_set)
# ISM层级判据: R(Si) == R(Si) ∩ A(Si)
if reach_set == intersection:
level_nodes.append(node)
if not level_nodes:
break # 防止死循环(如果有环路可能导致此情况)
levels[current_level] = level_nodes
# 从剩余节点中移除已分层的节点
for node in level_nodes:
active_nodes.remove(node)
current_level += 1
return levels
def generate_report(adj, reach, skel, levels):
"""生成综合分析报告"""
# 1. 邻接矩阵
print(f"\n{'='*25} 1. 邻接矩阵 (Adjacency Matrix) {'='*25}")
df_adj = pd.DataFrame(adj, index=labels, columns=labels)
print(df_adj)
# 2. 可达矩阵与 MICMAC 分析
print(f"\n{'='*25} 2. 可达矩阵与驱动力/依赖力 (MICMAC) {'='*25}")
df_reach = pd.DataFrame(reach, index=labels, columns=labels)
# 计算驱动力 (行和) 和 依赖力 (列和)
driving_power = df_reach.sum(axis=1)
dependence_power = df_reach.sum(axis=0)
# 添加到表格显示
df_display = df_reach.copy()
df_display['驱动力'] = driving_power
# 添加依赖力行 (需要转置处理一下再转回来,或者直接打印)
print(df_display)
print("-" * 60)
print(f"各因素依赖力 (列和):\n{dependence_power.to_dict()}")
# 3. 层级划分结果
print(f"\n{'='*25} 3. 层级划分结果 (Level Partition) {'='*25}")
print("说明:L1 为最顶层(结果层),L_Max 为最底层(原因层)")
for lvl, nodes in levels.items():
node_names = [full_labels[i] for i in nodes]
print(f"Level {lvl}: {', '.join(node_names)}")
# 4. 骨架矩阵
print(f"\n{'='*25} 4. 骨架矩阵 (Skeleton Matrix - 用于绘图) {'='*25}")
df_skel = pd.DataFrame(skel, index=labels, columns=labels)
print(df_skel)
# 5. 生成 Mermaid 代码
print(f"\n{'='*25} 5. Mermaid 可视化代码 {'='*25}")
print("将以下代码复制到 Markdown 编辑器即可直接生成层级图:\n")
mermaid_code = ["```mermaid", "graph BT"]
mermaid_code.append(" %% 节点定义")
for i in range(n):
# Mermaid 不接受嵌套括号,统一用方括号包裹文本
mermaid_code.append(f" {codes[i]}[\"{full_labels[i]}\"]")
mermaid_code.append("\n %% 边关系 (基于骨架矩阵)")
rows, cols = skel.shape
for r in range(rows):
for c in range(cols):
if skel[r, c] == 1:
mermaid_code.append(f" {codes[r]} --> {codes[c]}")
# 为了好看,按照层级添加子图 (Optional)
mermaid_code.append("\n %% 层级样式优化")
for lvl, nodes in levels.items():
nodes_str = ",".join([codes[i] for i in nodes])
# 给每一层的节点设置特定颜色
mermaid_code.append(f" class {nodes_str} level{lvl};")
# 定义颜色类
mermaid_code.append("\n classDef level1 fill:#f9d5e5,stroke:#333;")
mermaid_code.append(" classDef level2 fill:#eeac99,stroke:#333;")
mermaid_code.append(" classDef level3 fill:#e06377,stroke:#333,color:#fff;")
mermaid_code.append(" classDef level4 fill:#c83349,stroke:#333,color:#fff;")
mermaid_code.append("```")
print("\n".join(mermaid_code))
# ================= 执行计算 =================
# 1. 计算
adj_mat = calc_adjacency(n, relationships)
reach_mat = calc_reachability(adj_mat)
skel_mat = calc_skeleton(reach_mat)
levels_dict = calc_levels(reach_mat)
# 2. 输出报告
generate_report(adj_mat, reach_mat, skel_mat, levels_dict)
使用说明
macOS Homebrew 的 PEP 668 限制,不能直接往系统 Python 装包。最稳妥是用虚拟环境
python3 -m venv .venv
source .venv/bin/activate
python -m pip install numpy pandas
python main.py输出
source /Users/lushi78778/python/code/.venv/bin/activate
lushi78778@lushi78778deMac-mini code % source /Users/lushi78778/python/code/.venv/bin/activate
(.venv) lushi78778@lushi78778deMac-mini code % python main.py
========================= 1. 邻接矩阵 (Adjacency Matrix) =========================
S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12
S1 0 0 0 0 0 0 0 0 0 0 0 0
S2 0 0 1 0 0 0 0 0 0 0 0 0
S3 0 0 0 1 0 0 0 0 0 0 0 0
S4 0 0 0 0 0 0 0 0 0 0 0 0
S5 0 0 0 0 0 0 0 0 0 0 0 0
S6 0 0 0 0 1 0 1 0 1 1 0 0
S7 1 0 0 0 1 0 0 0 0 0 0 0
S8 0 0 0 0 0 0 0 0 0 0 0 0
S9 0 0 0 0 0 0 0 0 0 1 1 1
S10 0 0 0 0 0 0 0 0 0 0 0 0
S11 0 0 0 0 0 0 0 0 0 0 0 0
S12 0 0 0 0 0 0 0 1 0 0 1 0
========================= 2. 可达矩阵与驱动力/依赖力 (MICMAC) =========================
S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12 驱动力
S1 1 0 0 0 0 0 0 0 0 0 0 0 1
S2 0 1 1 1 0 0 0 0 0 0 0 0 3
S3 0 0 1 1 0 0 0 0 0 0 0 0 2
S4 0 0 0 1 0 0 0 0 0 0 0 0 1
S5 0 0 0 0 1 0 0 0 0 0 0 0 1
S6 1 0 0 0 1 1 1 1 1 1 1 1 9
S7 1 0 0 0 1 0 1 0 0 0 0 0 3
S8 0 0 0 0 0 0 0 1 0 0 0 0 1
S9 0 0 0 0 0 0 0 1 1 1 1 1 5
S10 0 0 0 0 0 0 0 0 0 1 0 0 1
S11 0 0 0 0 0 0 0 0 0 0 1 0 1
S12 0 0 0 0 0 0 0 1 0 0 1 1 3
------------------------------------------------------------
各因素依赖力 (列和):
{'S1': 3, 'S2': 1, 'S3': 2, 'S4': 3, 'S5': 3, 'S6': 1, 'S7': 2, 'S8': 4, 'S9': 2, 'S10': 3, 'S11': 4, 'S12': 3}
========================= 3. 层级划分结果 (Level Partition) =========================
说明:L1 为最顶层(结果层),L_Max 为最底层(原因层)
Level 1: S1(教学风格), S4(学习动机), S5(学习方法), S8(互动程度), S10(平台设计), S11(使用体验)
Level 2: S3(教学水平), S7(课程时长), S12(互动方式)
Level 3: S2(教学素养), S9(平台类型)
Level 4: S6(课程类型)
========================= 4. 骨架矩阵 (Skeleton Matrix - 用于绘图) =========================
S1 S2 S3 S4 S5 S6 S7 S8 S9 S10 S11 S12
S1 0 0 0 0 0 0 0 0 0 0 0 0
S2 0 0 1 0 0 0 0 0 0 0 0 0
S3 0 0 0 1 0 0 0 0 0 0 0 0
S4 0 0 0 0 0 0 0 0 0 0 0 0
S5 0 0 0 0 0 0 0 0 0 0 0 0
S6 0 0 0 0 0 0 1 0 1 0 0 0
S7 1 0 0 0 1 0 0 0 0 0 0 0
S8 0 0 0 0 0 0 0 0 0 0 0 0
S9 0 0 0 0 0 0 0 0 0 1 0 1
S10 0 0 0 0 0 0 0 0 0 0 0 0
S11 0 0 0 0 0 0 0 0 0 0 0 0
S12 0 0 0 0 0 0 0 1 0 0 1 0
========================= 5. Mermaid 可视化代码 =========================
将以下代码复制到 Markdown 编辑器即可直接生成层级图:
```mermaid
graph BT
%% 节点定义
S1["S1(教学风格)"]
S2["S2(教学素养)"]
S3["S3(教学水平)"]
S4["S4(学习动机)"]
S5["S5(学习方法)"]
S6["S6(课程类型)"]
S7["S7(课程时长)"]
S8["S8(互动程度)"]
S9["S9(平台类型)"]
S10["S10(平台设计)"]
S11["S11(使用体验)"]
S12["S12(互动方式)"]
%% 边关系 (基于骨架矩阵)
S2 --> S3
S3 --> S4
S6 --> S7
S6 --> S9
S7 --> S1
S7 --> S5
S9 --> S10
S9 --> S12
S12 --> S8
S12 --> S11
%% 层级样式优化
class S1,S4,S5,S8,S10,S11 level1;
class S3,S7,S12 level2;
class S2,S9 level3;
class S6 level4;
classDef level1 fill:#f9d5e5,stroke:#333;
classDef level2 fill:#eeac99,stroke:#333;
classDef level3 fill:#e06377,stroke:#333,color:#fff;
classDef level4 fill:#c83349,stroke:#333,color:#fff;
```
(.venv) lushi78778@lushi78778deMac-mini code 上一篇